Whisper is net als ChatGPT gemaakt door OpenAI. De tool helpt bij het omzetten van spraak naar tekst. Net als ChatGPT, gebruikt het hierbij geavanceerde taalmodellen. Whisper is open-source en wordt steeds breder ingezet. Zo helpt het binnen Home Assistant bij het omzetten van spraak naar tekst, ter ondersteuning van de spraak-assistent. In deze workshop laten we zien hoe je Whisper kunt gebruiken voor het maken van transcripties voor audio- of videobestanden.
Wat gaan we doen?
Het kan vaak nuttig zijn om een transcriptie of ondertitels te hebben voor bepaalde audio- of videobestanden. Denk bijvoorbeeld aan content voor YouTube, opgenomen vergaderingen, een podcast of een leerzame video. Dit kan tegenwoordig automatisch én vrijwel foutloos. Het maken van transcripties kan natuurlijk al langer, maar er zitten vaak veel missers bij. Dat zie je ook al aan de automatisch gegenereerde ondertitels op YouTube.
Natuurlijk is een goede omzetting best een uitdaging. De menselijke spraak is erg divers, met veel accenten en dialecten maar ook verschil in spreeksnelheid en intonatie. Er kunnen bovendien storende achtergrondgeluiden zijn zoals verkeer of bouwwerkzaamheden. Een spreker kan onduidelijk overkomen of onzeker zijn. Omdat woorden verschillende betekenissen kunnen hebben, kan ten slotte ook de context onderscheidend zijn.
Geholpen door ai zijn tegenwoordig heel nauwkeurige transcripties mogelijk. Teksten kunnen daarbij óók meteen worden vertaald. Dat laten we zien in deze workshop , waarin we met Whisper van OpenAI aan de slag gaan. We beginnen hierbij in de cloud met Google Colab. Daarna gaan we vertalingen maken vanaf een lokale pc. Dit versnelt in de meeste gevallen het hele proces. Het maakt je natuurlijk ook minder afhankelijk van de cloud.

We beginnen in de cloud met Google Colab, maar gaan daarna een lokale pc gebruiken, wat meestal het proces versnelt.
Wat is Whisper?
Whisper is een gratis en open-source tool van OpenAI. Deze organisatie ken je wellicht van de vraagbaak ChatGPT of van DALL·E 2 dat afbeeldingen kan genereren op basis van een omschrijving. De kracht van Whisper ligt bij het herkennen en omzetten van spraak in audio- en videobestanden. Dit kan voor het Engels en ongeveer honderd andere talen, waaronder Nederlands.
Je kunt Whisper op een eigen pc installeren. Het werkt dan volledig offline. Wel helpt het als je een stevig systeem hebt. Een stevige grafische kaart kan het proces enorm versnellen, zoals we zullen demonstreren. Whisper is getraind met een grote dataset met veel variaties van menselijke spraak. Mede daardoor kan het heel nauwkeurige vertalingen maken. Je kunt zelf de omvang van het model kiezen, waarbij een groter model nauwkeuriger is maar ook fors meer rekenkracht vereist.
Wat heb je nodig?
Voor het werken met Whisper heb je niet perse een pc nodig. Je kunt gebruik maken van cloud computing. Dat kan – omdat het een Python-project is – zelfs gratis met Google Colab. Daar beginnen we in deze workshop daarom ook mee. Wil je niet afhankelijk zijn van een clouddienst, dan kun je Whisper ook lokaal op je pc installeren. De software is namelijk open-source. Voor aanvullende informatie kun je op de GitHub-pagina (https://github.com/openai/whisper) terecht
Verderop in deze workshop behandelen we een lokale installatie in meer detail. Hiervoor heb je overigens wel een capabel systeem nodig, anders zal het maken van de transcripties erg lang duren. Om het rekenwerk te versnellen gaan we een grafische kaart van Nvidia gebruiken. Heb je die niet, dan werkt alles ook, maar moet je wat meer geduld hebben.
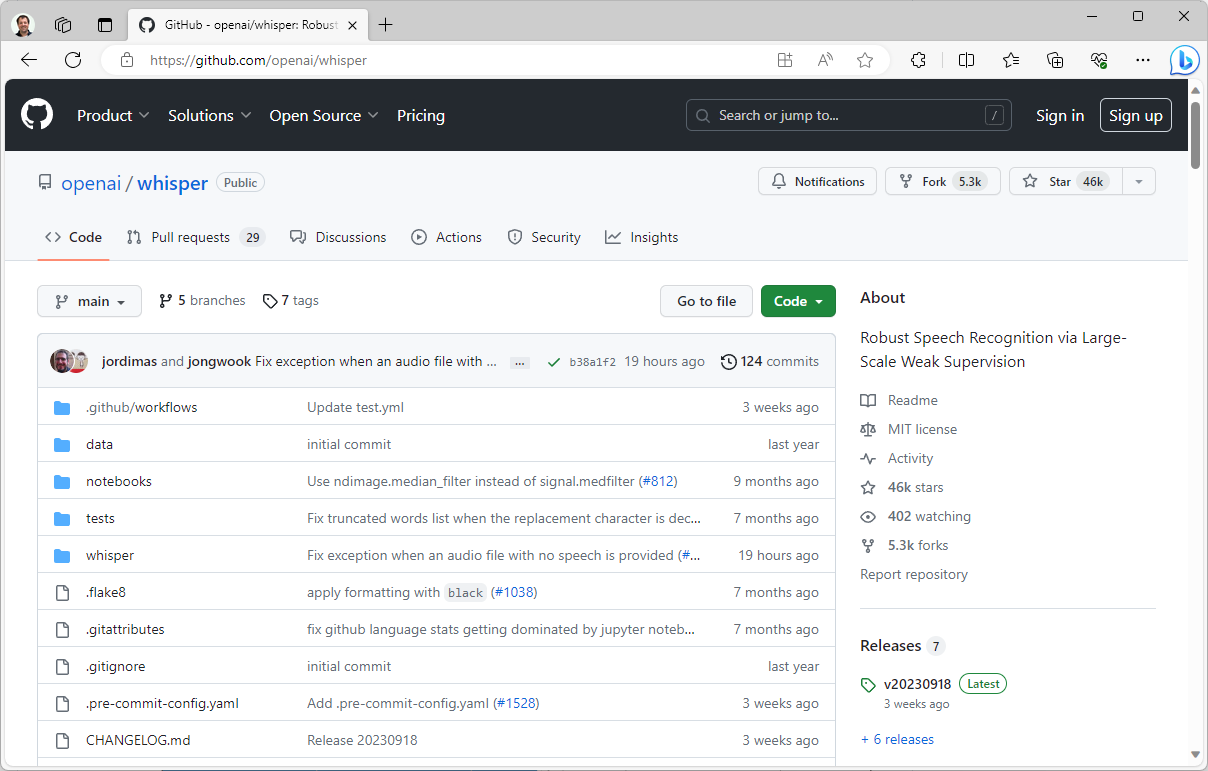
Verschillende modellen
Je kunt bij het werken met Whisper uit verschillende modellen kiezen, oplopend in omvang. De meertalige modellen heten achtereenvolgens tiny, base, small, medium en large. Bij het werken met Whisper moet je uit één van deze modellen kiezen. Er zijn ook modellen voor exclusief de Engelse taal. Deze heten tiny.en, base.en, small.en en medium.en. Hoewel je voor Engels ook gewoon de meertalige modellen kunt gebruiken, zijn deze specifieke Engelstalige modellen wat nauwkeuriger. Al merk je dat vooral bij de kleinere modellen tiny.en en base.en.
We kiezen in deze masterclass steeds voor het medium model, met voor Engels de .en-versie. Probeer en vergelijk zeker de kleinere modellen als je een minder zwaar systeem hebt of minder tijd.
Bronbestanden downloaden
Je kunt voor Whisper allerlei soorten mediabestanden gebruiken. Dat kunnen natuurlijk ook je eigen opnames zijn! In deze workshop gebruiken we voor de demonstratie vier video’s van YouTube met een speelduur van zo’n 15 tot 25 minuten. Het betreft de volgende video’s:
- Een Engelse video (met Duits accent) van Christian Lempa over zijn Home Lab (https://www.youtube.com/watch?v=mGVj5W0RbHo).
- Een Nederlandse vlog van Linda Meijers over wonen in Zweden (https://www.youtube.com/watch?v=d-QU0dPVVlY)
- Een Nederlandse video over het stoppen met fossiele brandstoffen van Arjen Lubach (https://www.youtube.com/watch?v=5k6aY60WYok).
- Een Chinese video met onbekende inhoud (https://www.youtube.com/watch?v=LvYmCvak-M4) van één de populairste Chinese YouTube-kanalen, bedoeld voor het testen van de vertalingen.
Via X2Mate.com (https://x2mate.com/) downloaden we de YouTube-video’s als mp4-bestand in 720p voor verwerking in Whisper. We hadden eventueel ook alleen de audio in mp3-formaat kunnen downloaden. Voor de beoordeling is het videobestand met ingebakken audio echter makkelijker. Whisper maakt namelijk automatisch een ondertitelbestand (in .srt-formaat). Veel videospelers kunnen dit bestand laten zien tijdens het afspelen van de video. Hierdoor kun je direct het resultaat beoordelen. Vergelijk het eventueel met de automatisch gegenereerde ondertitels van YouTube!
In de cloud
Dankzij Google Colab kun je Whisper in de cloud draaien zonder enige kosten. We leggen uit hoe je hier gebruik van maakt. Elders in deze workshop behandelen we ook een lokale installatie op je eigen pc.
Google Colab
Je kunt voor weinig geld cpu-kracht in de cloud huren. Voor gpu-kracht betaal je vaak veel meer. Google Colab (https://colab.research.google.com) biedt het allemaal voor niks. In feite is Colab (voluit ‘Colaboratory’) een Python-omgeving in de cloud. Je kunt deze omgeving gewoon via een browser benaderen met een gratis Google-account. Door de opmars van grafisch intensieve ai-toepassingen, vaak met Python als basis, is het platform van Google flink in trek. Al maakt dit het ook wat onzeker of deze dienst kan blijven bestaan en gratis blijft.
We laten verderop in deze workshop ook zien hoe je lokaal op je eigen pc kunt werken met Whisper.
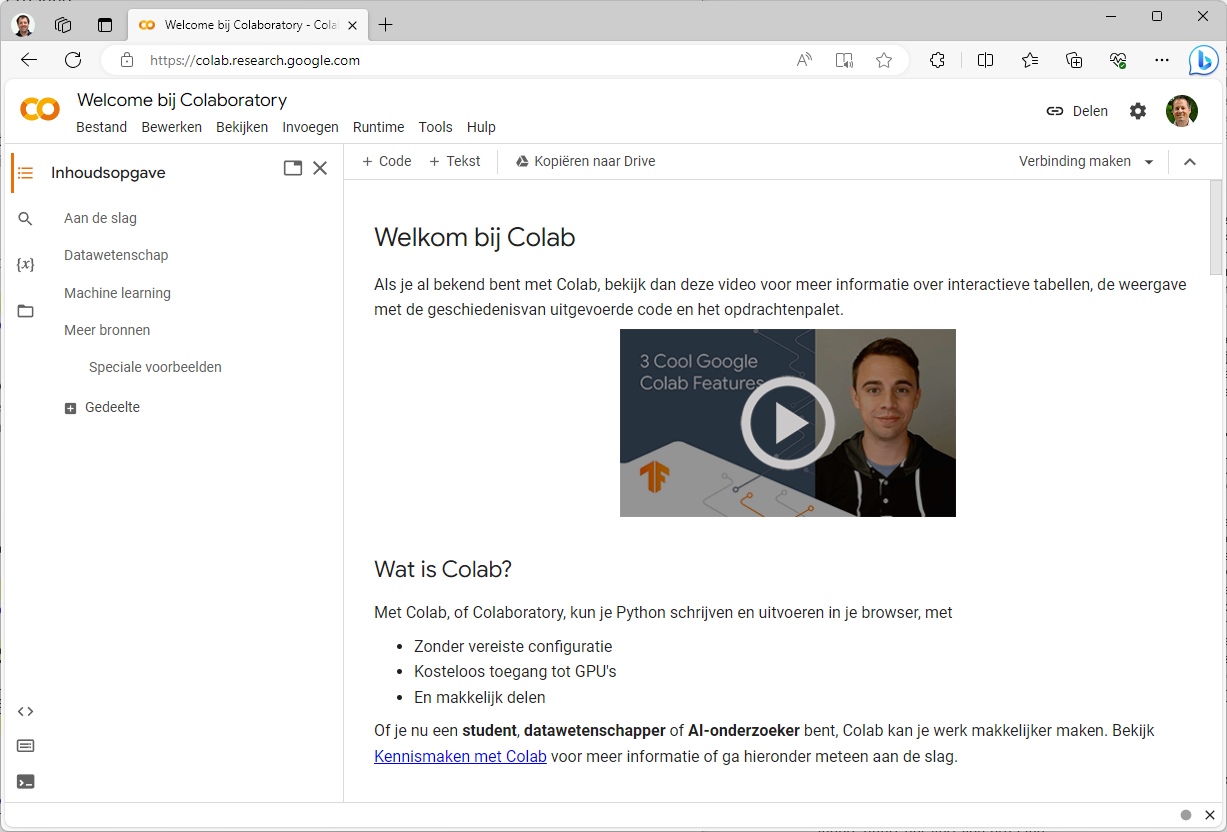
Koppeling met Google Drive
We beginnen in Google Drive (https://drive.google.com). Zorg dat je bent ingelogd met je Google-account. Je kunt Colab als app koppelen. Kies daarvoor Nieuw / Meer / Meer apps koppelen. Vul in het zoekveld Google Colaboratory in. Klik op de bewuste app en kies dan Installeren. Na het doorlopen van de stappen is Google Colaboratory gekoppeld aan je Google Drive en kun je het venster sluiten.
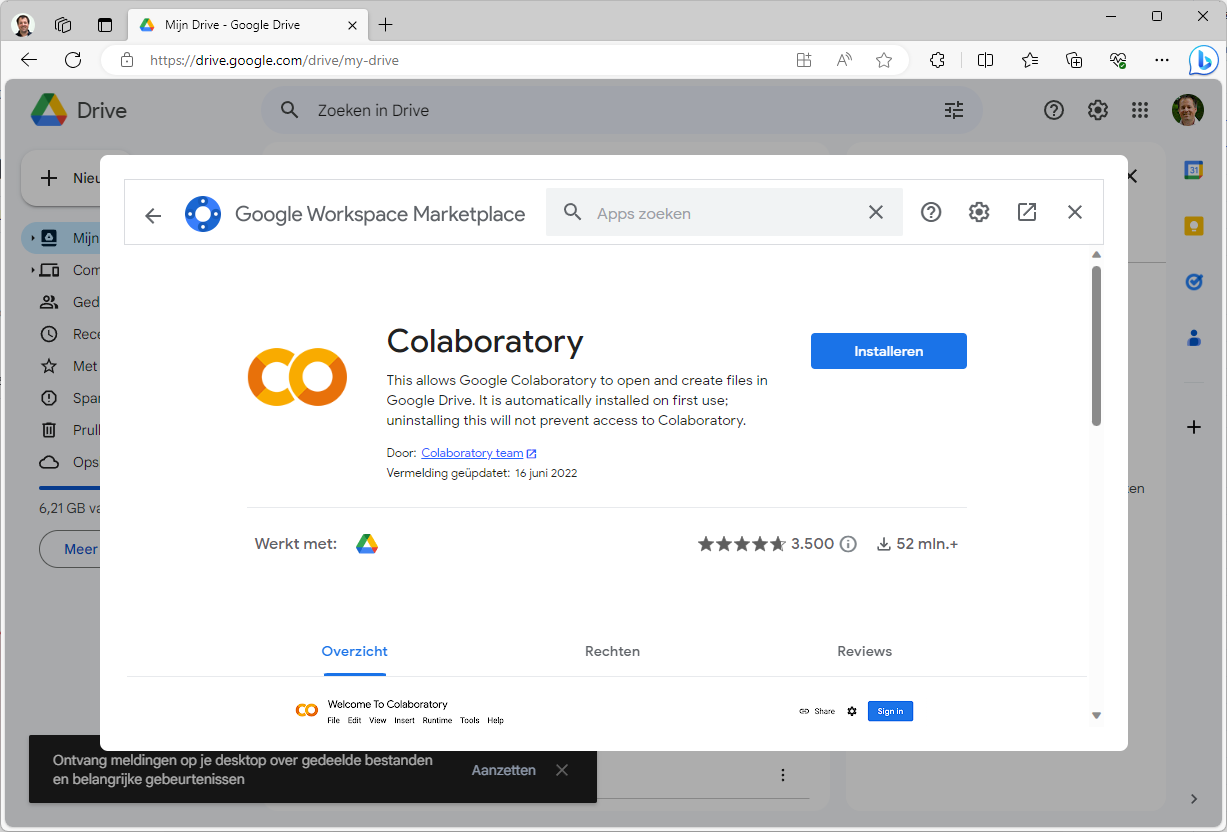
Whisper installeren
Nadat de app is gekoppeld kun je onder Nieuw / Meer direct Google Colaboratory kiezen. Linksboven kun je eventueel de naam van het project (Untitled0.jpynb) veranderen. We maken hier YouTube-demo.jpynb van. Kies in het menu Runtime voor Runtimetype wijzigen. Selecteer onder Hardwareversnelling een gpu. De beschikbaarheid kan variëren. In dit voorbeeld kiezen we T4 GPU. Klik dan op Opslaan. De grafische kracht zal automatisch in ons project worden benut.
Plak de onderstaande opdrachten in het tekstvak achter het uitvoerenicoontje en voer het uit. Daarmee wordt Whisper geïnstalleerd en FFmpeg. Dit framework zorgt dat alle denkbare mediabestanden kunnen worden gedecodeerd.
!pip install git+https://github.com/openai/whisper.git !sudo apt update && sudo apt install ffmpeg
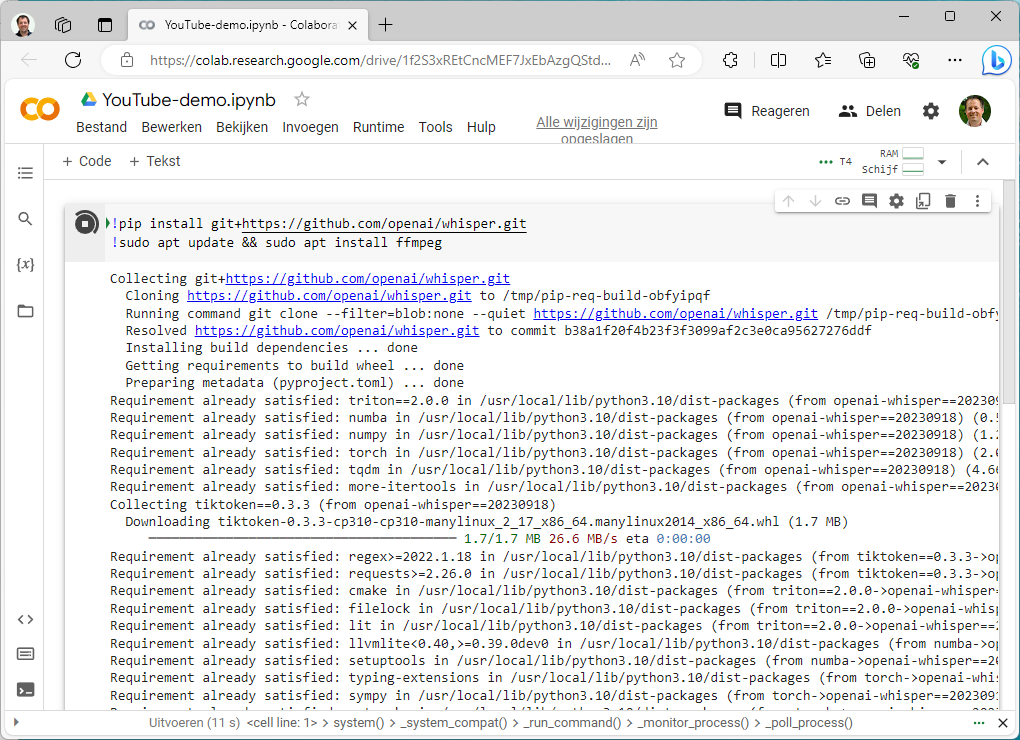
Mediabestanden uploaden
We gebruiken de in een eerdere stap gedownloade bestanden van YouTube en geven deze een makkelijke naam om mee te werken, te weten homelab.mp4, zweden.mp4 en brandstoffen.mp4. Om te zorgen dat je binnen Colab met deze bestanden kunt werken gaan we ze eerst uploaden naar de cloud. Klik daarvoor op het bestandenicoontje links in Colab. Je kunt de gewenste videobestanden slepen naar het bestandsvenster of uploaden via het uploadicoontje.
Zorg dat je de originele bestanden ook zelf op je pc hebt. Als je de omgeving verlaat zal de zogenoemde runtime worden verwijderd. Daarmee verdwijnen ook de geüploade bestanden. Je zult ze de volgende keer opnieuw moeten uploaden. Ook zul je dan overigens weer het correcte runtimetype moeten kiezen en Whisper moeten installeren.
Transcripties maken
Binnen Google Colab kun je nu met de bestanden gaan werken. Het is dus tijd om Whisper aan het werk te zetten met de gekozen videobestanden. Kijk eerst of je Whisper kunt aanroepen met de opdracht !whisper. Je ziet dan ook de optionele parameters. We beginnen met de Engelse video en kiezen het model medium.en. Klik op +Code en voer de onderstaande opdracht in, waarin we zoals je ziet het bestand en het model specificeren.
!whisper "homelab.mp4" --model medium.en
Voor de twee andere Nederlandstalige video’s gebruiken we --model medium. Dat is een meertalig model met hoge nauwkeurigheid. De taal zal steeds automatisch worden herkend.
!whisper "zweden.mp4" --model medium !whisper "brandstoffen.mp4" --model medium
Google had zo’n drie tot zes minuten per video nodig om de transcripties te maken. Na afloop kun je de tekstbestanden downloaden, waaronder het ondertitelbestand (.srt). Vanuit het bestandsvenster kun je alle tekstbestanden downloaden naar je pc. Zie je de nieuwe bestanden niet direct, klik dan op het icoontje Vernieuwen!
Vertalingen maken
Je kunt met Whisper ook vertalingen maken. Dat is heel praktisch als je bijvoorbeeld zelf een YouTube-video hebt gemaakt die ook internationaal wordt bekeken. Je kunt dan voor de originele taal (bijvoorbeeld Nederlands) een ondertitelingsbestand maken maar daarnaast óók verschillende vertalingen maken, zoals Duits en Engels, en die aanbieden bij YouTube.
Met de opdracht hieronder kun je een Engelstalige transcriptie maken voor een Nederlandstalige video. Het vraagt waarschijnlijk iets meer nabewerking, maar een groot deel van het werk is in ieder geval al voor je gedaan.
!whisper "brandstoffen.mp4" --model medium --task translate --language en
We hebben Whisper ook gevraagd om de Chinese video te vertalen naar het Engels. Met het ondertitelingsbestand dat hiermee is gemaakt is de video nu goed te volgen.
!whisper "china.mp4" --model medium --task translate
Resultaat bekijken
De meeste videospelers zullen automatisch ondertitels laten zien als je het ondertitelbestand in dezelfde map zet en ook dezelfde naam geeft als je videobestand. Soms moet je nog een optie aanzetten om de ondertitels te kunnen zien. Je zult zien dat de transcripties steeds van hele hoge kwaliteit zijn. Versprekingen zijn vaak al gecorrigeerd. De video’s zijn ook veel beter te volgen dan met de automatische transcriptie die YouTube zelf aanbiedt. Ook wordt veel beter en nauwkeuriger gebruik gemaakt van leestekens.
Soms zul je nog wat kleine aanpassingen willen maken voor bijvoorbeeld enkele exclusieve woorden die verkeerd zijn geïnterpreteerd. Dat gaat natuurlijk heel eenvoudig in het tekstbestand zelf, maar er zijn ook tools die je voor srt-bestanden kunt gebruiken.

Lokale installatie
Je kunt Whisper op een eigen pc installeren en gebruiken. Hiervoor heb je onder andere Python en Git nodig. We laten zien hoe je het installeert en gebruikt.
Python en Git installeren
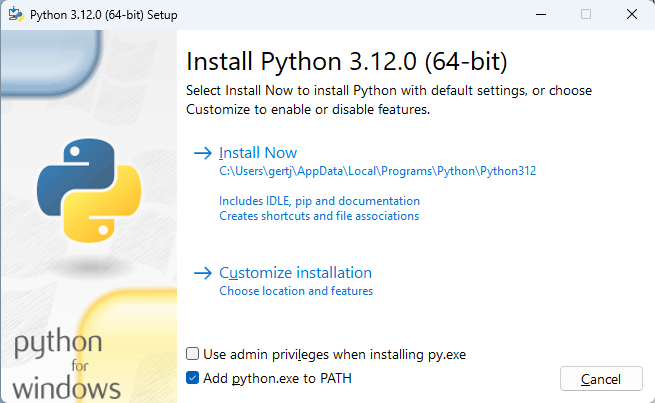
Een lokale installatie onder Windows is zeker niet lastig, maar er is best wat software vereist om alles te laten werken. Om te beginnen moet je Python downloaden en installeren (https://www.python.org/downloads/). Hoewel een wat oudere versie wordt aangeraden, zijn we geen problemen tegengekomen bij gebruik van de meest recente versie 3.12.x. Let er bij de installatie van Python op dat je een vinkje zet bij Add python.exe to PATH. Je kunt Python dan vanuit elke map op de pc aanroepen.
Installeer vervolgens ook Git voor Windows (https://git-scm.com/download/win). Bij deze installatie kun je alle standaardopties accepteren. Belangrijk is dat Git daarbij ook weer aan de path wordt toegevoegd.
Grafische kaart
Heb je een grafische kaart van Nvidia dan kun je de berekeningen van Whisper flink versnellen, zoals we verderop zullen laten zien. Hiervoor dien je CUDA te installeren. We gebruiken versie 11.8 (https://developer.nvidia.com/cuda-11-8-0-download-archive). Selecteer op de downloadpagina Windows met de architectuur x86_64 en selecteer je versie van Windows (doorgaans 10 of 11). De hier gekozen versie van CUDA wordt ook door PyTorch ondersteund dat we in de volgende stap gaan installeren.
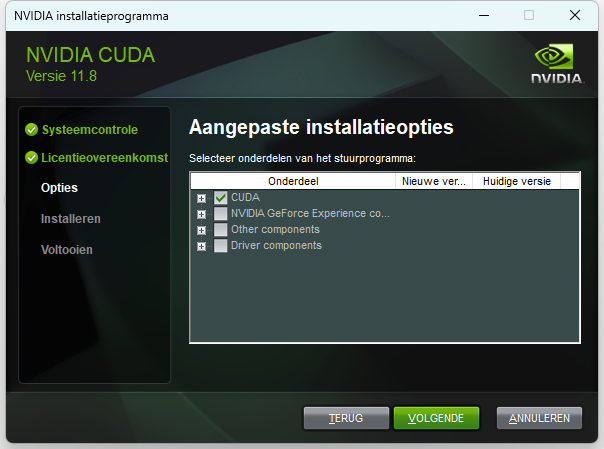
Doorloop de installatie. Kies daarbij in het venster Installatieopties voor Aangepast (geavanceerd). Vink vervolgens alle onderdelen uit behalve CUDA. Zo voorkom je dat onder andere de huidige drivers voor je grafische kaart worden vervangen door een oudere versie.
FFmpeg installeren
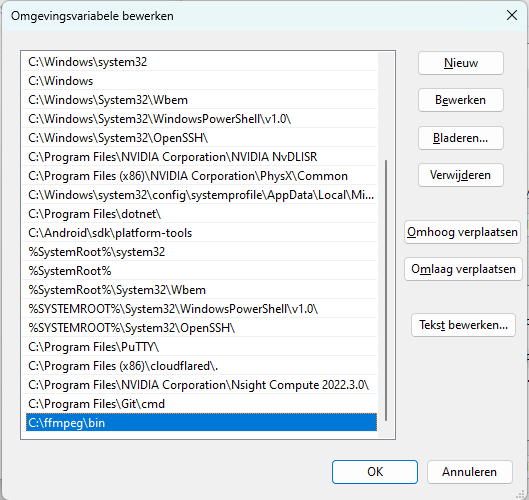
Je hebt ook bij een lokale installatie het framework FFmpeg nodig. Ga daarvoor naar de downloadpagina (https://ffmpeg.org/download.html), klik op het Windows-icoontje en kies Windows builds from gyan.dev. Download het archief (ffmpeg-git-full.7z) en pak het uit met de ingebakken tool van Windows of bijvoorbeeld 7-Zip. Hernoem de map naar ffmpeg en verplaats deze naar de C:-schijf. Het bestand ffmpeg.exe bevindt zich dan in C:\ffmpeg\bin.
De hierboven genoemde map gaan we aan de path toevoegen. Klik op Win+R, vul in sysdm.cpl en druk op Enter. Open dan het tabblad Geavanceerd en kies Omgevingsvariabelen. Dubbelklik op Path. In het venster klik je op Nieuw om een pad toe te voegen. Vul dan in C:\ffmpeg\bin. Bewaar de aanpassingen en herstart je systeem.
PyTorch
Zet alle videobestanden waarvoor je een transcriptie wil maken in een map. Klik dan in Windows-verkenner rechts op een lege plek in de map en kies Openen in terminal. Als het goed is kun je nu alle opdrachten uitvoeren voor geïnstalleerde toepassingen zoals python --version, ffmpeg en git. We gaan eerst een recente versie van PyTorch installeren dat nodig is voor Whisper. Ga daarvoor naar de website van PyTorch (https://pytorch.org/get-started/locally/) en kies de opties Stable, Windows, Pip, Python en CUDA 11.8. Kopieer het commando.
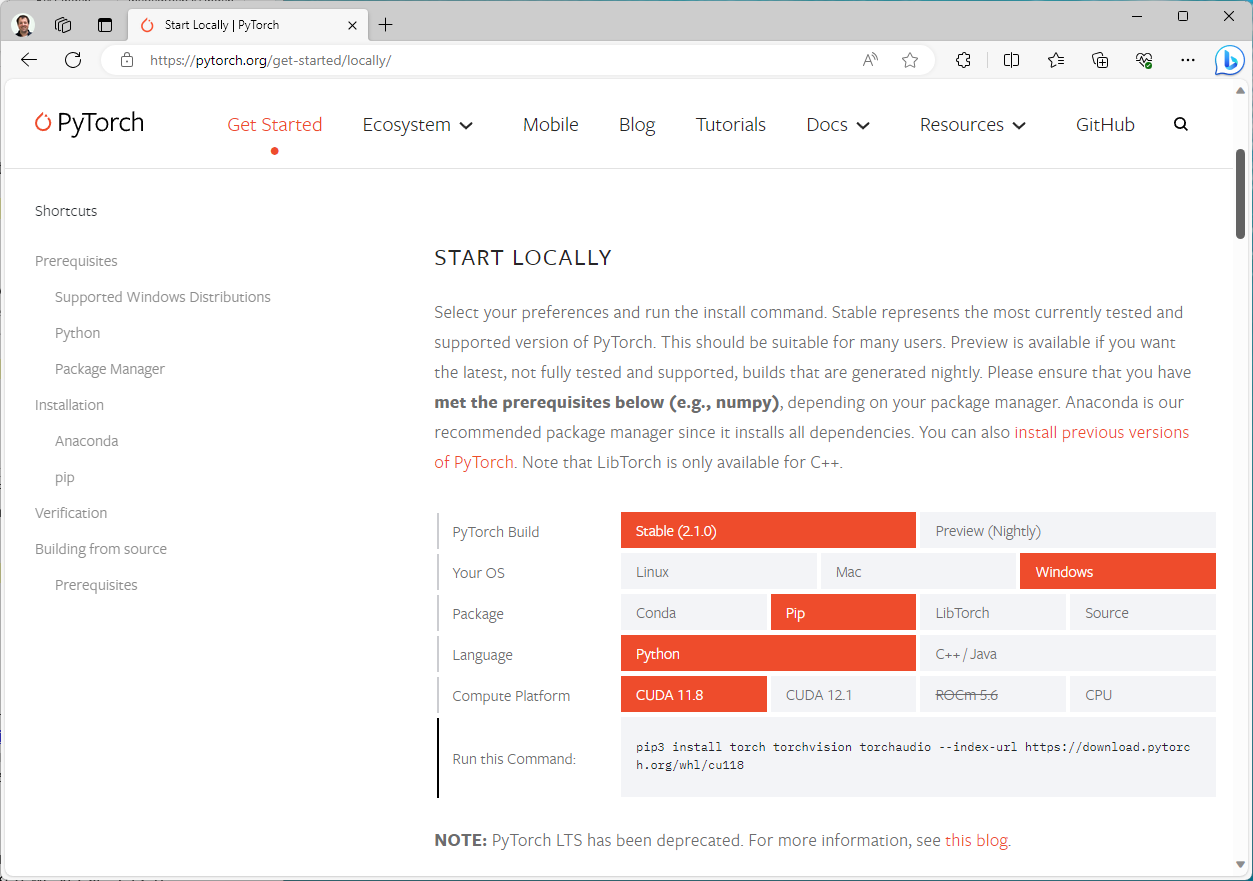
In ons voorbeeld ziet het commando er uit zoals hieronder:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Voer de opdracht die je had gekregen uit in de terminal. Kom je geen problemen tegen, ga dan verder met de volgende opdrachten:
pip3 install setuptools-rust pip3 install git+https://github.com/openai/whisper.git
De installatie van Whisper is nu als het goed is geslaagd, zodat we straks daadwerkelijk de transcripties kunnen gaan maken.
Controleer CUDA
Transcripties maken met de processor is tijdrovend. Zelfs op een 16-core AMD Ryzen 9 5950X is voor de transcriptie van zweden.mp4 ruim 20 minuten nodig. De processor wordt daarbij steeds met zo’n 70% wordt belast. Met een grafische kaart, in ons voorbeeld een RTX 3080, lukt het binnen 3 minuten met een veel lagere belasting. Een grafische kaart is dus zeker geen overbodige luxe. Dat hoeft geen RTX 3080 te zijn. Er is vooral genoeg vram nodig. Een RTX 2060 of RTX 3060 helpt al enorm, maar je zult zeker verschil merken als je een snellere kaart in je systeem prikt.
Je kunt binnen Python controleren of CUDA beschikbaar is. Start daarvoor Python met python. Voer dan na elkaar de volgende opdrachten in. Je krijgt als het goed is True als resultaat.
import torch torch.cuda.is_available()
Transcripties maken met Whisper
De opdrachten voor het maken van de transcriptie verschillen niet van de eerder genoemde opdrachten in Google Colab:
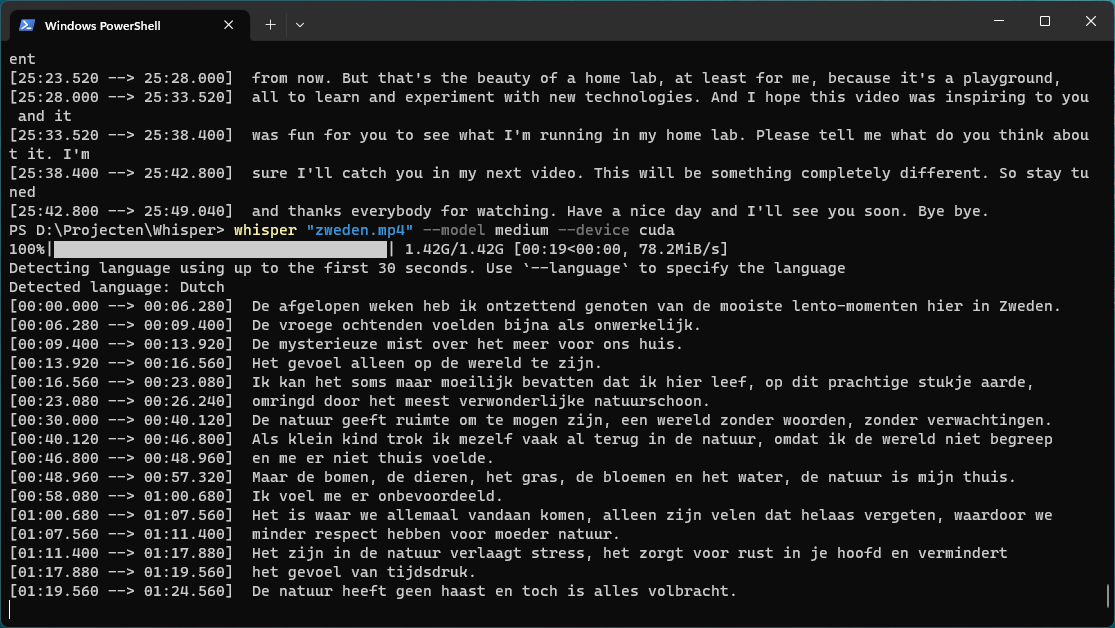
whisper "homelab.mp4" --model medium.en whisper "zweden.mp4" --model medium whisper "brandstoffen.mp4" --model medium
Als CUDA beschikbaar is zal automatisch de grafische kaart worden gebruikt. Geholpen door een RTX 3080 grafische kaart vragen de transcripties ongeveer drie tot vijf minuten. Dit ligt in lijn met de snelheid via Colab. Heb je geen grafische kaart of geen CUDA? Dan zal de processor worden gebruikt, wat zoals aangegeven flink veel extra tijd kost. Je kunt dat zelf ervaren met de optie --device cpu. Dit forceert het gebruik van de processor. Als CUDA wél beschikbaar is geeft deze opdracht overigens een waarschuwing.