De opmars van generatieve ai is niet te stoppen. Teksten, afbeeldingen en video’s komen steeds vaker uit de koker van de ai-hulpjes van bedrijven als OpenAI, Google en Microsoft. Er zijn wel zorgen over authenticiteit, auteursrecht en privacy. Om meerdere redenen wordt het aantrekkelijker om lokaal te werken met ai. Dat kan met open-source taalmodellen, zoals het nieuwe Llama 3 van Meta, dat wordt ingebouwd in WhatsApp en Instagram. In deze workshop gaan we een volledig lokale ChatGPT bouwen met Ollama en verschillende modellen.
Wat is Ollama?
De software Ollama (https://ollama.com) zorgt dat je op je eigen pc met open-source taalmodellen kunt werken. Via de opdrachtprompt kun je vragen stellen, zoals je dat kent van ChatGPT. De software kun je onder andere binnen Windows installeren. Ollama kan met een groot aantal open-source taalmodellen werken. Bekende voorbeelden zijn Llama 3, Llama 2, Mistral, LLaVA en Gemma. Op de website (https://ollama.com/library) vind je een overzicht.
Llama 3, het nieuwe model van Meta, is een interessante optie. Het zal onder meer gebruikt gaan worden in WhatsApp en Instagram. Voor het trainen van dit model is een zeven keer zo grote dataset gebruikt als bij het eerder verschenen Llama 2.

Wat is nodig voor Ollama?
Ollama werkt op elke moderne pc met bijvoorbeeld Windows of Linux. De meeste taalmodellen zijn goed bruikbaar op een gemiddelde pc. De grotere modellen vragen echter wel een snellere processor en meer werkgeheugen, anders reageren ze duidelijk trager. Aan 4 tot 16 GB werkgeheugen heb je overigens wel genoeg maar er zijn wat uitschieters naar boven.
Kleinere modellen kunnen in potentie (met andere tools) op een smartphone worden gedraaid. Grote modellen worden liefst geholpen door een stevige pc met grafische kaart van Nvidia. In deze workshop werken we onder Windows, waar we een grafische kaart op basis van de RTX 3080 van Nvidia kunnen inzetten. Daardoor kunnen we wat grotere modellen gebruiken. Onder Linux kan zo’n grafische kaart overigens ook worden aangesproken. Het installatiescript houdt daar ook rekening mee.
Een internetverbinding is alleen nodig voor het installeren van de software, modellen en updates, niet voor het werken met de chatbot. Wat opslagcapaciteit betreft is voor elk model ongeveer 5 GB ruimte nodig. Kleinere modellen zijn soms wel minder nauwkeurig, al worden er stappen mee gemaakt. Bezwaarlijker is dat ze door de kleinere dataset vaak beter in het Engels dan het Nederlands werken. Daarom gaan we binnen Ollama óók aan de slag met een goed Nederlands taalmodel.
Installatie van Ollama
De installatie van Ollama is eenvoudig. Onder Windows kun je een standaard installatieprogramma gebruiken. We raden aan om deze op te halen via de pagina met releases op GitHub (https://github.com/ollama/ollama/releases). Daar kun je de laatste versie downloaden en lees je over de recente veranderingen.
De installatie onder Linux is iets omslachtiger. Maar het installatiescript helpt enorm. Die handelt ook de installatie van cuda af, voor toegang tot een grafische kaart van Nvidia. Verder zorgt het voor de installatie van de binaire bestanden, het maken van een groep en gebruiker, en de installatie van een servicescript (systemd) zodat Ollama automatisch wordt gestart en blijft draaien.
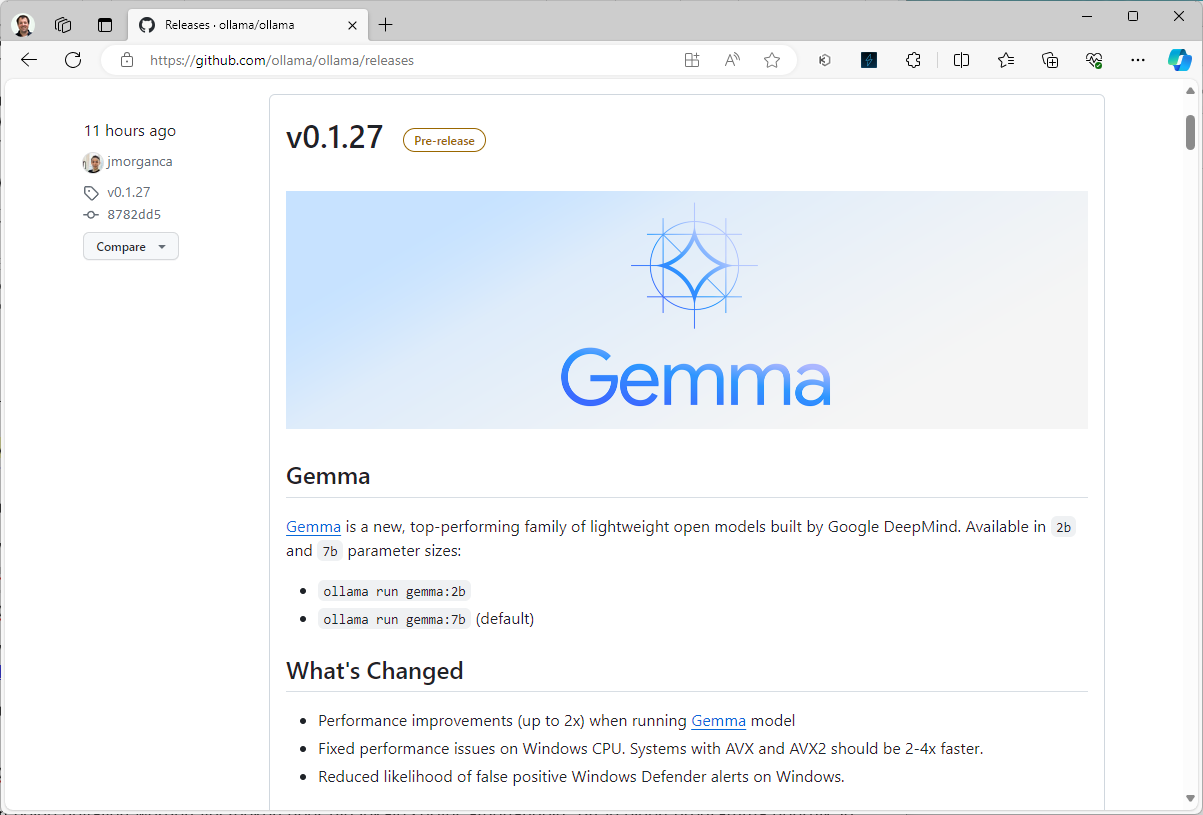
Zorg dat je Ollama up-to-date houdt om met nieuwe modellen te kunnen werken. Versie 0.1.27 is bijvoorbeeld geschikt voor het nieuwe Gemma-model van Google. Vanaf versie 0.1.34 kun je met Llama 3 werken, het nieuwe model van Meta. Na de installatie kun je Ollama met het gewenste model starten via een opdrachtprompt en opdrachten geven. Ollama nestelt zich ook in je systeempictogrammen, waar je de toepassing eventueel kunt afsluiten.
Zo werkt Ollama
Ollama werkt op de achtergrond met een lokale server voor het afhandelen van verzoeken. Die software leunt op de zeer populaire softwarebibliotheek lama.cpp, wat ook de reden is dat zoveel modellen worden ondersteund. Voor het geven van de opdrachten kun je een standaard geïnstalleerde client gebruiken. Daarvoor open je een opdrachtprompt en geef je een opdracht die begint met ollama.
Je kunt ook zelf een programma ontwikkelen dat Ollama gebruikt. Maar ook dan moet je verzoeken door die lokale server laten afhandelen via een zogeheten api. In alle gevallen werkt Ollama volledig lokaal en is geen internettoegang nodig. Tijdens het starten van Ollama geef je het gewenste model op, zoals je verderop zult zien.
Veel open-source modellen zijn beschikbaar op websites als Kaggle, Hugging Face, Nvidia NeMo en Google Vertex AI. Modellen downloaden is voor Ollama echter niet nodig: de toepassing beheert zelf de downloads. De manier waarop het werkt doet wat dat betreft een beetje aan Docker denken, maar dan voor ai.

Opdrachten geven
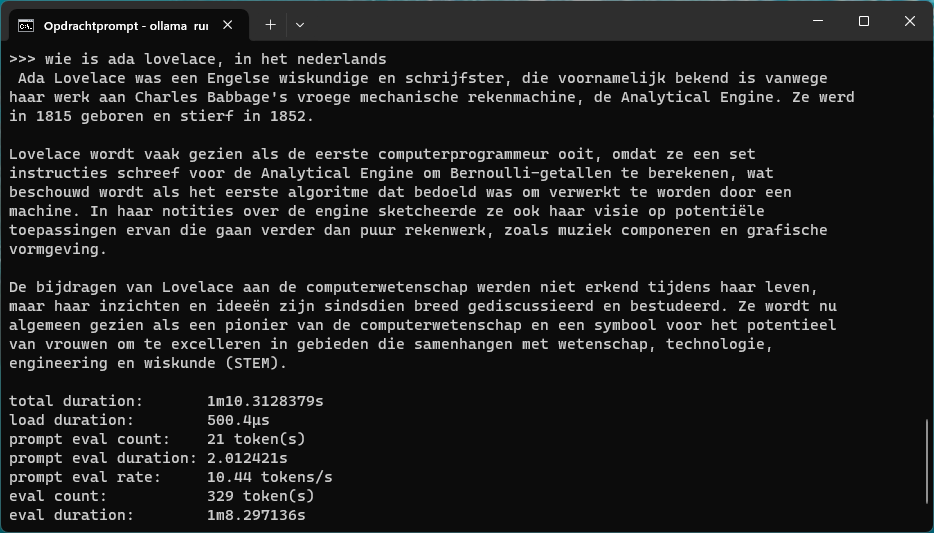
Wil je Ollama starten met een bepaald model, dan gebruik je de opdracht ollama run gevolgd door het gewenste model . Geef je bijvoorbeeld de opdracht ollama run mistral dan wordt het bekende model Mistral automatisch opgehaald als dat nog niet eerder is gedaan. Daarna kun je direct vragen stellen. Er zijn eventueel extra instellingen beschikbaar. Met /set kun je zien welke dat zijn. Zo kun je met /set verbose bijvoorbeeld statistieken inzien om de prestaties te kunnen beoordelen. Wil je de uitvoer stoppen, gebruik dan Ctrl+D.
Alle opdrachten die je geeft worden op de achtergrond zoals gezegd niet door de client zelf maar door de lokale server afgehandeld, die altijd actief is en klaar voor het afhandelen van verzoeken. Dat roept wellicht vragen op over het geheugengebruik, mede gelet op de vaak forse omvang van taalmodellen. Gelukkig is alleen tijdens het gebruik en tot ongeveer vijf minuten daarna veel geheugen nodig. Daarna komt Ollama in een soort ruststand.
Populaire modellen
Ollama nodigt natuurlijk uit om te experimenteren met allerlei modellen. Houd hierbij wel rekening met de omvang van modellen. De meeste zijn zo’n 5 GB groot maar er zijn ook wat uitzonderingen van wel 40 GB of meer. Voor grotere modellen is ook meer geheugen nodig om ze goed te draaien. Ze passen doorgaans ook niet in het geheugen van een videokaart, wat je zult merken aan de prestaties.
Er zijn veel modellen om te proberen. Mistral (mistral) is een interessant open-source model om mee te beginnen met goede prestaties. Sinds kort is ook Gemma (gemma) beschikbaar, een nieuw taalmodel van Google dat volgens het bedrijf is gebaseerd op hetzelfde onderzoek en dezelfde technologie als het gesloten model Gemini. Ook kun je Llama-2 (llama2) proberen, een open-source taalmodel van Meta dat is geoptimaliseerd voor chat.
Andere goede opties zijn het aan Llama verwante model Code Llama (codellama) dat is geoptimaliseerd voor programmacode. LLaVA (llava) is een model waarmee je kunt vragen om afbeeldingen te beschrijven, dit komt elders in deze workshop ook kort aan bod. We geven ook tips voor modellen die specifiek voor de Nederlandse taal zijn getraind.
Het nieuwe Llama 3
Het nieuwe Llama 3 van Meta (llama3) is een interessante optie, mede gezien de sterk verbeterde prestaties. Het zou nog beter zijn in taken als het genereren van coherente en relevante tekst, het begrijpen van vragen en produceren van zinvolle antwoorden, het classificeren van tekst in categorieën en het samenvatten van tekst. Leuk detail is dat het (op termijn) wordt ingebouwd in diensten als WhatsApp en Instagram.

Extra opties voor modellen
Je kunt bij sommige modellen het aantal parameters specificeren, zoals gemma:2b of gemma:7b. Bij Llama-2 heb je naast llama2:7b bijvoorbeeld llama2:13b en llama2:70b. Het aantal parameters, zoals 7b of 13b, geeft de complexiteit van het model aan en de hoeveelheid trainingsgegevens die beschikbaar zijn. Het meest gangbaar is 7b. Meer parameters betekent dat complexere structuren kunnen worden herkend en voorspeld, maar er is ook meer rekenkracht nodig. Daarom werkt het 70b-model van Llama-2 relatief traag en vraagt het veel geheugen, tot ongeveer 64 GB.
Er is een trend naar efficiëntere modellen. Zo zou het 7b-model van Gemma bijvoorbeeld al krachtiger zijn dat het 13b-model van Llama-2, waardoor je dus minder zware hardware nodig hebt voor vergelijkbare of betere resultaten.
Er kunnen ook variaties van taalmodellen zijn. Zo biedt Code Llama (codellama) de varianten instruct, python en code. Je gebruikt zo’n variant met bijvoorbeeld ollama run codellama:7b-instruct. Hierbij is instruct gericht op het in menselijke taal helpen bij programmacode, een beetje zoals ChatGPT dat doet. De variant python is gespecialiseerd in de programmeertaal Python. En de variant code is gericht op het beoordelen van code en oplossen van fouten. Heb je taalmodellen lokaal opgehaald in verschillende varianten? Met ollama list kun je zien welke dat zijn.
Ondersteuning Nederlandse taal
Een nadeel van veel open-source modellen is dat ze zijn getraind met overwegend Engelse teksten. De resultaten kunnen tegenvallen als je zulke modellen in het Nederlands gebruikt. Sterker nog: zelfs als je vraagt om in het Nederlands te antwoorden, komt er meestal toch een Engelstalig antwoord. Deze problemen worden nog versterkt in kleinere modellen. Vallen de resultaten tegen, probeer daarom zeker eens dezelfde prompt in het Engels.
Gelukkig zijn er wel enkele modellen die goed werken in het Nederlands. Ook bestaan er enkele modellen die zelfs specifiek voor de Nederlandse taal zijn gemaakt. De mogelijkheden gaan we in de volgende stappen voor je verkennen.

Werken met Mixtral
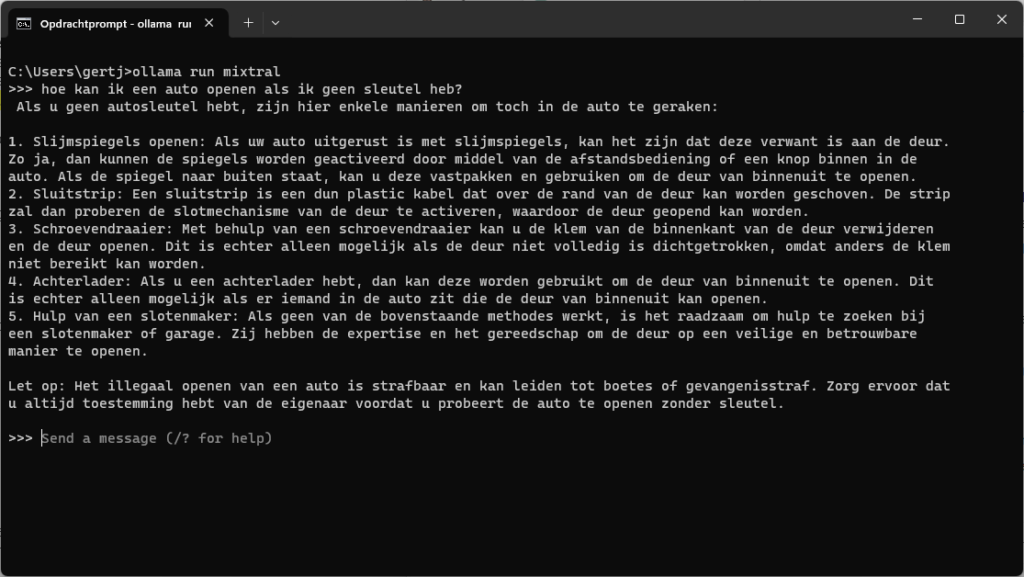
Namen we het relatief uitgebreide Mixtral (mixtral) als voorbeeld, van dezelfde makers als Mistral, dan is het volgens het bedrijf geoptimaliseerd voor Engels, Frans, Duits, Spaans en Italiaans. Het is daarom maar beperkt met Nederlandse teksten getraind, al gaat het daar nog relatief goed mee overweg. In het voorbeeld vragen we hoe je een auto kunt openen als je geen sleutel hebt. Het blijkt hier geen censuur toe te passen zoals je dat vaak ziet bij chatbots, maar het komt wel terecht met een disclaimer.
Het hobbyproject GEITje
Het is best een uitdaging om een goed Nederlands taalmodel te vinden. Er wordt wel aan de ontwikkeling daarvan gewerkt. Zoals GPT-NL, dat een open model wordt, en 13,5 miljoen aan subsidie kreeg. Er zijn wat interessante ‘hobbyprojecten’, zoals het door Edwin Rijgersberg opgezette GEITje. Dit is gebaseerd op Mistral 7B en getraind met teksten afkomstig van onder meer websites, forums, boeken, rechtspraak, ondertitels en nieuwsartikelen. Bob Lucassen heeft hier een groot aandeel in: hij stelde het Nederlandse corpus samen met zo’n 234 GB aan gevarieerde platte tekst.
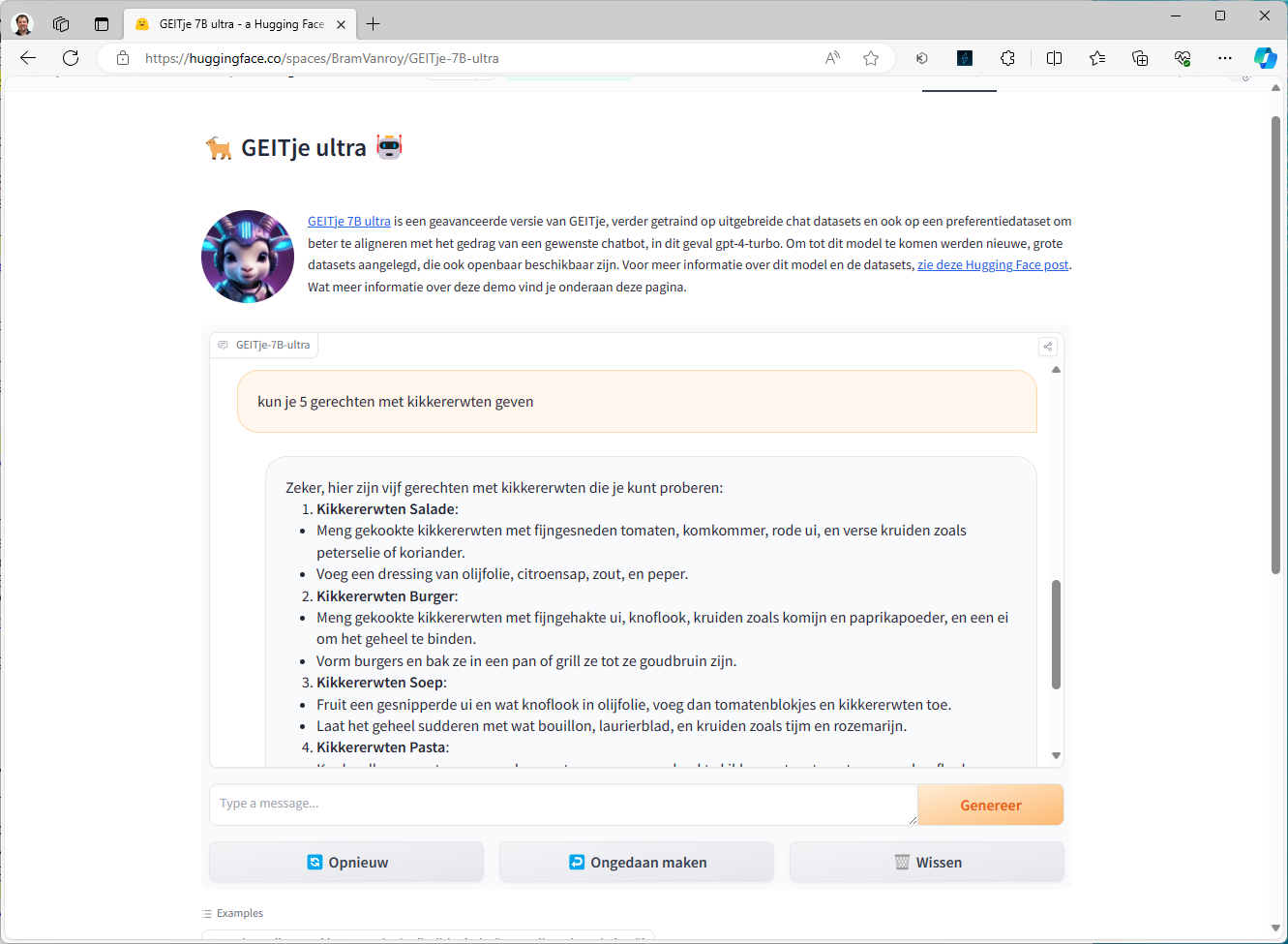
Van GEITje zijn overigens ook twee chat-varianten gemaakt onder de namen GEITje-chat en GEITje-chat-v2. Verder is er een ‘ultra’ variant gemaakt door Bram Vanroy, onderzoeker aan de KU Leuven. Deze variant is nog verder getraind op chat-datasets. Via Hugging Face kun je eventueel demo’s voor deze modellen proberen (zie bijvoorbeeld https://huggingface.co/spaces/BramVanroy/GEITje-7B-ultra). De chatbots kunnen instructies opvolgen, vragen beantwoorden en dialogen houden over allerlei onderwerpen.
Je kunt GEITje en de varianten overigens relatief eenvoudig gebruiken binnen Ollama. Dat gaan we in de volgende stap doen.
Model opbouwen
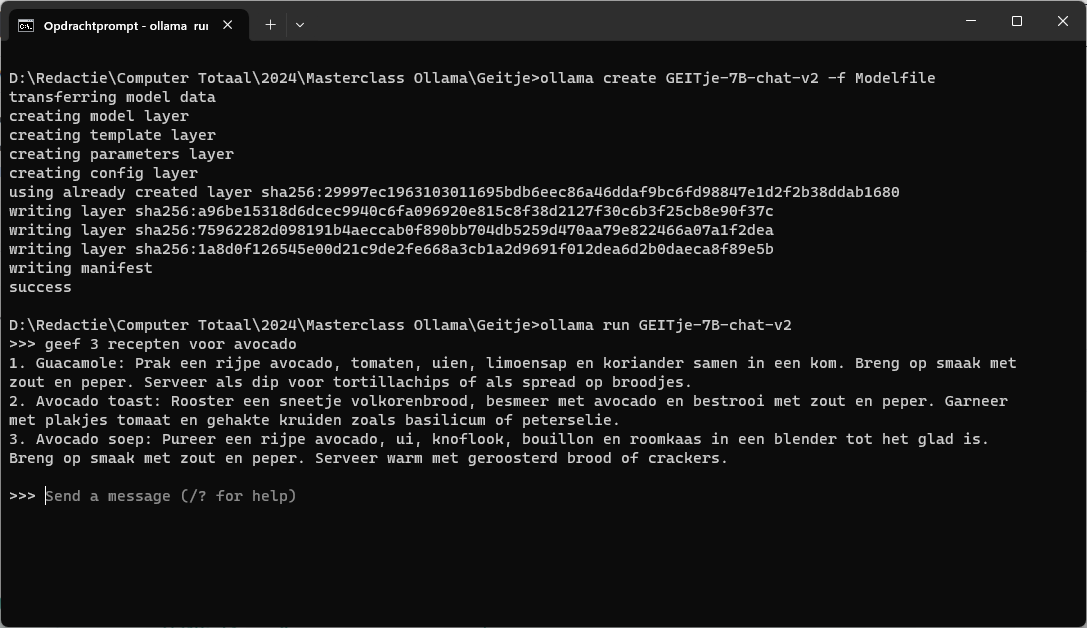
Om GEITje binnen Ollama te gebruiken moet je een zogenoemde gguf-variant downloaden. Dat is een bestandsformaat waar Ollama, of eigenlijk het achterliggende lama.cpp, mee werkt. Je kunt het gguf-model voor GEITje-7B-chat-v2.gguf ophalen op https://huggingface.co/Rijgersberg/GEITje-7B-chat-v2-gguf/tree/main. Zet het bestand in een map.
Je hebt voorts ook een zogenoemde Modelfile nodig. Dit bevat een beschrijving van het model voor Ollama en gewenste parameters. Voor GEITje kun je dit bestand ophalen via https://github.com/Rijgersberg/GEITje/blob/main/ollama/Modelfile. Zet deze Modelfile in dezelfde map. Daarna kun je binnen Ollama een model opbouwen door in die map de opdracht ollama create GEITje-7B-chat-v2 -f Modelfile te geven. Overigens, het deel -f Modelfile mag je eventueel weglaten als je Modelfile precies die bestandsnaam heeft.
Na een korte wachttijd is het model binnen Ollama beschikbaar. Met ollama list kun je dat controleren. Je gebruikt het model vervolgens met ollama run GEITje-7B-chat-v2.
Aangepast model
Via een zogenoemde Modelfile kun je desgewenst een nieuw model met kleine aanpassingen maken. Daarin kun je dan bijvoorbeeld beschrijven hoe de assistent zich moet gedragen. Als voorbeeld maken we een bestand Modelfile met daarin de volgende inhoud:
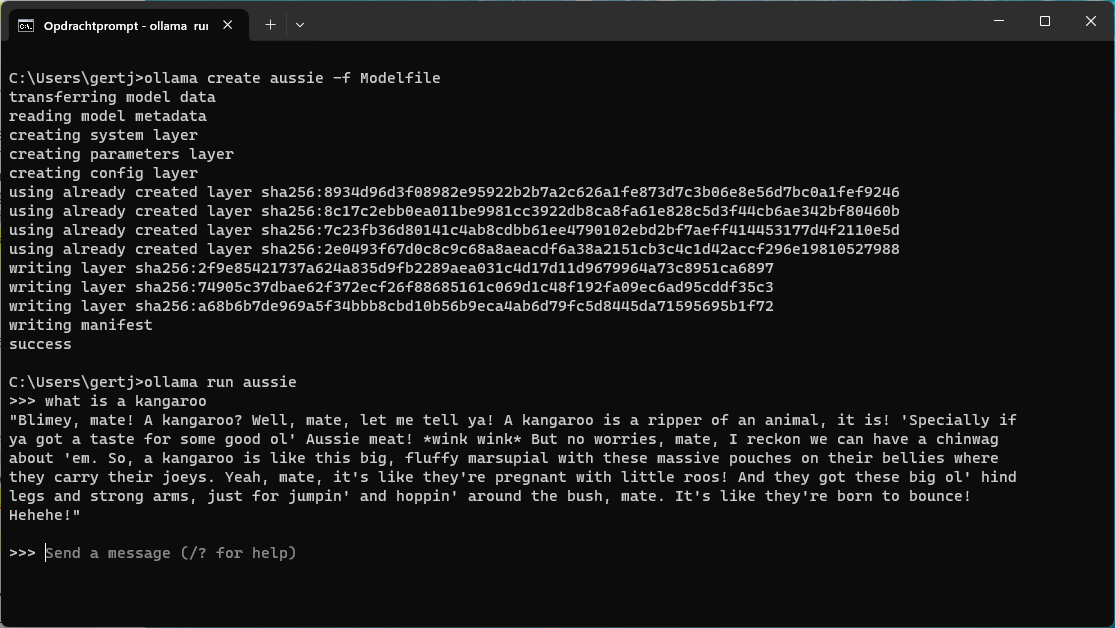
FROM llama2 PARAMETER temperature 1 SYSTEM Answer like someone with an Australian accent
We nemen hier zoals je kunt zien Llama-2 als basis. Via de parameter temperature geef je feitelijk aan hoe creatief de assistent moet antwoorden. Een lage waarde (zoals 0.2) geeft vaak saaie reacties die wel consistent en conservatief zijn, een hoge waarde brengt meer creativiteit, wat in dit geval meer gepast is. Een standaardwaarde is doorgaans 0.8 wat een goed uitgangspunt is. Hier kiezen we 1 voor extra creativiteit.
Je kunt nu eenvoudig het nieuwe model maken. We zullen dit aussie noemen en maken het model met de opdracht ollama create aussie -f Modelfile. Daarna start je het met ollama run aussie. Je zult merken dat de assistent steeds een stevig Australisch accent gebruikt en gevatte antwoorden geeft.
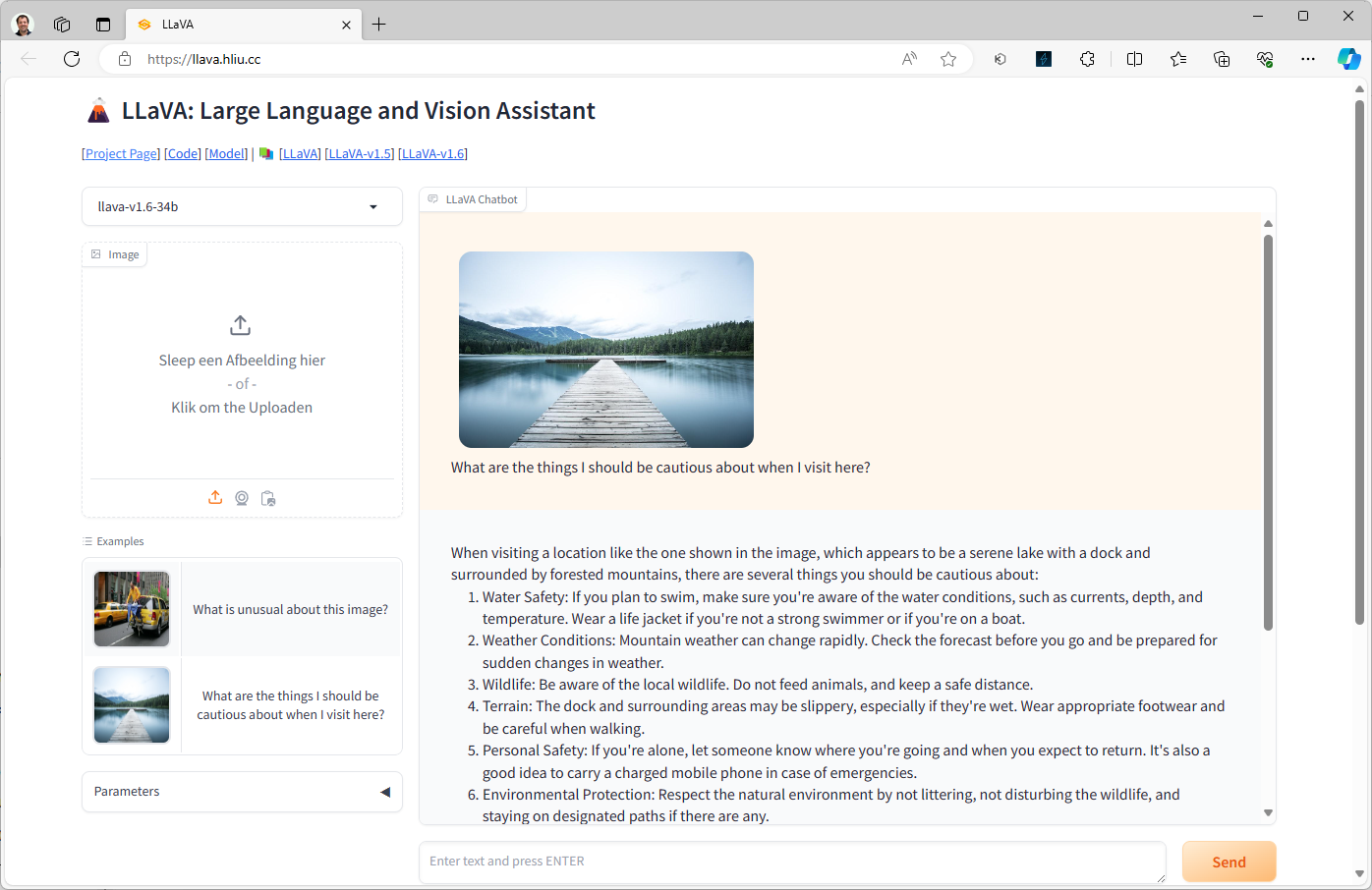
Afbeeldingen beschrijven
Ollama kan geen afbeeldingen of video’s genereren op basis van een prompt. Wel is er ondersteuning voor het model LLaVA (Large Language and Vision Assistant) waarmee je afbeeldingen kunt laten interpreteren. Hierdoor kun je bijvoorbeeld vragen om een bepaalde afbeelding te omschrijven, of andere vragen over een afbeelding stellen.
Je kunt LLaVA gewoon binnen Ollama gebruiken met de opdracht ollama run llava. Daarna kun je een vraag stellen en daarin een bestandslocatie van een afbeelding meegeven. Er is ook een online demo op https://llava.hliu.cc waar je de voorbeelden kunt bekijken of een afbeelding kunt uploaden en een eigen prompt invoeren.